Is Disaggregated Prefill/Decode a Silver Bullet for LLM Serving?#
- Date:
2026-03-10
Abstract#
Disaggregated prefill/decode has gained traction as a promising architecture for LLM serving, separating the compute-intensive prefill phase from the memory-bound decode phase onto dedicated node groups. Proponents argue that this separation enables independent scaling and eliminates interference between the two phases. But is it truly a silver bullet? This article puts the claim to the test by evaluating disaggregated prefill/decode using vLLM with NIXL over the AWS Elastic Fabric Adapter (EFA) on a 4-node cluster. We compare data parallelism and simple load-balanced routing as baselines against disaggregated configurations. Our results show that while disaggregation dramatically reduces inter-token latency (ITL), it comes at a significant cost to throughput and time-to-first-token (TTFT), revealing that the architecture is far from a universal solution.
Introduction#
In standard LLM serving, each node handles both prefill and decode for incoming requests. The prefill phase is compute-bound and processes the entire input prompt in parallel, while the decode phase is memory-bandwidth-bound and generates tokens autoregressively. When both phases share the same GPU pool, long prefill requests can block decode iterations, increasing inter-token latency for concurrent requests.
Disaggregated prefill/decode addresses this interference by assigning prefill
and decode to separate node groups. After a prefill node completes prompt
processing, the KV cache is transferred to a decode node via a high-bandwidth
interconnect. NIXL [1] (NVIDIA Inference Xfer Library) provides the KV cache
transfer mechanism, and on AWS, this transfer occurs over EFA using the
LIBFABRIC backend.
The appeal is intuitive: by isolating decode nodes from prefill interference, token generation should proceed at a steady, low-latency pace. However, this separation introduces new costs — KV cache transfer overhead, prefill node saturation at long input lengths, and reduced effective cluster capacity for each phase. The question is whether these trade-offs are worthwhile compared to simpler alternatives like data parallelism or stateless load-balanced routing.
This experiment uses vLLM [2] with the
NixlConnector to orchestrate disaggregated serving, and vllm-router [3] as
a reverse proxy to load-balance requests across node groups. The experiment
code is available under src/nixl in the companion repository.
Container Image#
The experiment uses a custom Docker image that bundles all required components.
The Dockerfile builds on nvidia/cuda:12.8.1-devel-ubuntu24.04 and
installs the following stack:
GDRCopy v2.5.1 for GPU-direct memory registration
EFA installer v1.47.0 for AWS Elastic Fabric Adapter support
UCX v1.20.0 built with verbs, rdmacm, and EFA transport
NIXL v0.10.1 with
LIBFABRICbackend for KV cache transfernixlbench for standalone NIXL bandwidth/latency microbenchmarks
PyTorch 2.9.1, flash-attn 2.8.1, and DeepGEMM v2.1.1.post3
vLLM 0.15.1 with
NixlConnectorsupportvllm-router for load-balancing across disaggregated node groups
The image is built and saved as a portable tarball via the Makefile:
make docker && make save
This produces nixl-latest.tar.gz, which is distributed to all Slurm nodes
at launch time via pigz decompression and docker load.
Serving Script#
The vllm.sbatch script orchestrates multi-node vLLM serving on Slurm. It
accepts two key flags that control the serving topology:
--route R: splits the allocated nodes intoRidentical groups, each running an independent vLLM instance. Avllm-routerprocess on the head node round-robins requests across groups.--prefill P: within each group, assignsPnodes as prefill-only (kv_producer) and the remaining nodes as decode-only (kv_consumer). KV cache transfer between prefill and decode nodes usesNixlConnectorwith theLIBFABRICbackend over EFA.
When --prefill 0 (default), all nodes in a group run standard data-parallel
serving. The script computes DP = nodes_per_group * (8 / TP) and launches
vLLM with --data-parallel-size accordingly.
For disaggregated mode, each prefill and decode node runs as an independent vLLM process with explicit KV transfer configuration:
# Prefill node
vllm serve ... \
--kv-transfer-config.kv_connector NixlConnector \
--kv-transfer-config.kv_role kv_producer \
--kv-transfer-config.kv_connector_extra_config.backends+ LIBFABRIC
# Decode node
vllm serve ... \
--kv-transfer-config.kv_connector NixlConnector \
--kv-transfer-config.kv_role kv_consumer \
--kv-transfer-config.kv_connector_extra_config.backends+ LIBFABRIC
The router uses round_robin policy for pure-DP groups and
consistent_hash with --vllm-pd-disaggregation for PD groups, directing
initial requests to prefill endpoints and subsequent decode traffic to decode
endpoints:
# Router for pure-DP groups (round-robin across group endpoints)
vllm-router \
--policy round_robin \
--worker-urls http://<GROUP0_IP>:8000 http://<GROUP1_IP>:8001 \
--host 0.0.0.0 --port 8010
# Router for PD disaggregation (consistent hash with prefill/decode split)
vllm-router \
--policy consistent_hash \
--vllm-pd-disaggregation \
--prefill http://<PREFILL0_IP>:8000 \
--decode http://<DECODE0_IP>:8001 --decode http://<DECODE1_IP>:8002 \
--host 0.0.0.0 --port 8010
Each container is launched with --privileged, --net=host, and explicit
/dev/infiniband/uverbs* and /dev/gdrdrv device mounts to enable
GPU-direct RDMA over EFA.
Benchmark Script#
The bench.sh script wraps vllm bench serve and handles Docker image
loading transparently. If the vllm CLI is not available on the host, the
script re-executes itself inside the container. It points the benchmark client
at the router endpoint (or the direct vLLM endpoint for single-group
configurations):
bash bench.sh -H <ROUTER_IP> -p <ROUTER_PORT> -- \
--model /fsx/models/deepseek-ai/DeepSeek-V2-Lite \
--dataset-name random \
--random-input-len 512 --random-output-len 256 \
--num-prompts 1024
Experimental Setup#
All experiments run on 4 nodes with 8 GPUs each (TP=8) using
DeepSeek-V2-Lite as the model. The benchmark uses random input/output data
with 1024 prompts via vllm bench serve.
The configurations are:
Baseline (data parallelism): 4 nodes, TP=8, DP=4. All nodes serve both prefill and decode. This is the standard data-parallel serving setup.
Route 2: 2 groups of 2 nodes each, TP=8, DP=2 per group. A router round-robins requests across groups. Each group independently handles both prefill and decode.
Route 4: 4 groups of 1 node each, TP=8, no data parallelism. A router distributes requests across all 4 independent nodes.
PD 1P3D: Disaggregated prefill/decode with 1 prefill node and 3 decode nodes. KV cache is transferred from the prefill node to decode nodes via NIXL.
PD 2P2D: Disaggregated prefill/decode with 2 prefill nodes and 2 decode nodes.
# Exp 1: Baseline — 4 nodes, TP=8, pure DP
salloc -N 4 bash vllm.sbatch \
--model /fsx/models/deepseek-ai/DeepSeek-V2-Lite \
--gpu-memory-utilization 0.9
# Exp 2: 2 groups × 2 nodes, DP=2 per group, router round-robins
salloc -N 4 bash vllm.sbatch --route 2 \
--model /fsx/models/deepseek-ai/DeepSeek-V2-Lite \
--gpu-memory-utilization 0.9
# Exp 3: 4 groups × 1 node, no DP, router round-robins
salloc -N 4 bash vllm.sbatch --route 4 \
--model /fsx/models/deepseek-ai/DeepSeek-V2-Lite \
--gpu-memory-utilization 0.9
# Exp 4: 1 prefill + 3 decode
salloc -N 4 bash vllm.sbatch --prefill 1 \
--model /fsx/models/deepseek-ai/DeepSeek-V2-Lite \
--gpu-memory-utilization 0.9
# Exp 5: 2 prefill + 2 decode
salloc -N 4 bash vllm.sbatch --prefill 2 \
--model /fsx/models/deepseek-ai/DeepSeek-V2-Lite \
--gpu-memory-utilization 0.9
Results#
We evaluate each configuration along four metrics: output token throughput, request throughput, time to first token (TTFT), and inter-token latency (ITL). Each plot contains two panels — the left panel sweeps input length with a fixed output length of 256 tokens (prefill-dominated regime), while the right panel sweeps output length with a fixed input length of 512 tokens (decode-dominated regime). This allows us to observe how each configuration behaves when the workload shifts from prefill-heavy to decode-heavy.
Microbenchmark: KV Cache Transfer Bandwidth#
Before examining end-to-end serving results, we use nixlbench to measure
the raw NIXL transfer bandwidth over EFA between two nodes. This establishes
an upper bound on KV cache transfer speed and helps contextualize the TTFT
overhead observed in disaggregated configurations.
The benchmark runs in Multi-GPU (MG) mode with all 8 GPUs per node performing
VRAM-to-VRAM transfers over the LIBFABRIC backend:
salloc -N 2 bash nixl.sbatch --backend LIBFABRIC \
--initiator_seg_type VRAM --target_seg_type VRAM \
--mode MG --num_initiator_dev 8 --num_target_dev 8
Block Size (B) Batch Size B/W (GB/Sec) Avg Lat. (us) P99 Tx (us)
---------------------------------------------------------------------------------
4096 1 0.670064 6.1 47.0
8192 1 1.315392 6.2 45.0
16384 1 2.511416 6.5 47.0
32768 1 4.820423 6.8 50.0
65536 1 8.733224 7.5 56.0
131072 1 12.341950 10.6 52.0
262144 1 23.272188 11.3 59.0
524288 1 43.365764 12.1 62.0
1048576 1 74.816773 14.0 77.0
2097152 1 121.086563 17.3 105.0
4194304 1 180.631395 23.2 146.0
8388608 1 239.037623 35.1 247.0
16777216 1 289.500030 58.0 432.0
33554432 1 327.436372 102.5 796.0
67108864 1 349.608429 192.0 1724.0
Mapping to DeepSeek-V2-Lite KV cache transfer. DeepSeek-V2-Lite uses
Multi-head Latent Attention (MLA), which compresses the KV cache into a latent
vector per token per layer. The per-token-per-layer KV cache size is
(kv_lora_rank + qk_rope_head_dim) × dtype_size = (512 + 64) × 2 = 1,152 bytes.
For 512 input tokens across 27 layers, the total KV cache is approximately 15.2 MB.
With TP=8, each GPU transfers about 1.9 MB, which falls in the ~121 GB/s
bandwidth range per the table above. Without tensor parallelism, the full 15.2 MB
transfer achieves approximately ~289 GB/s.
Output Token Throughput#
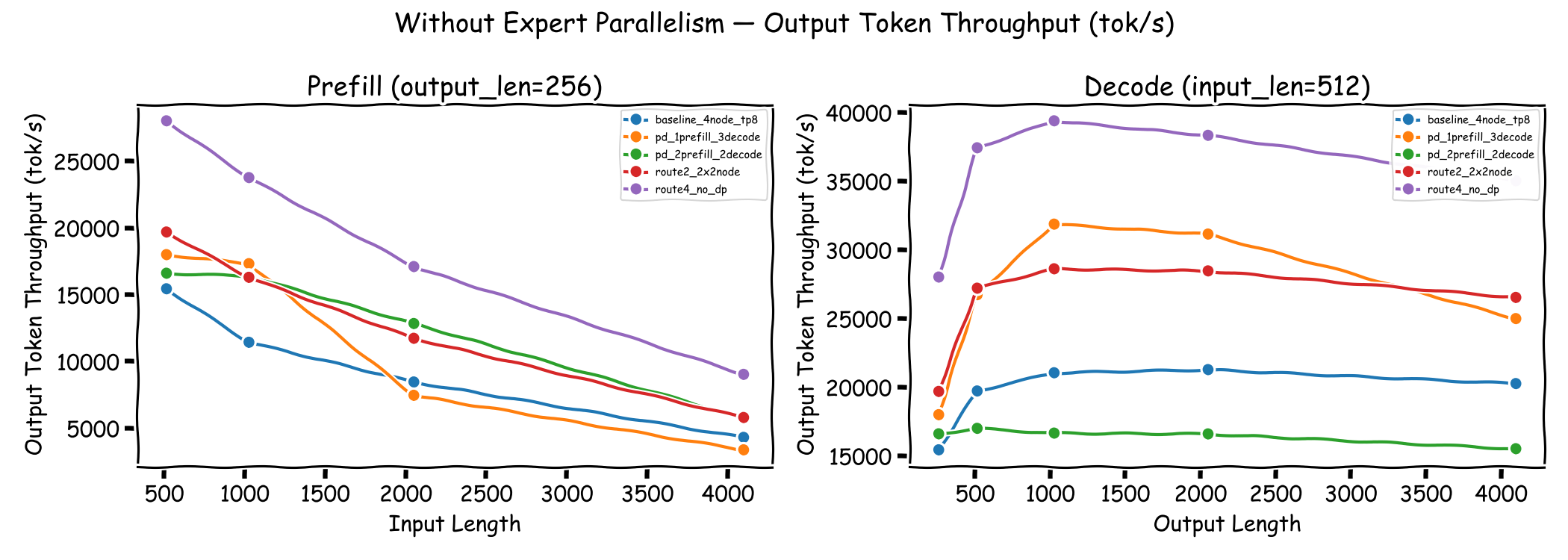
The left panel varies input length with a fixed output length of 256 tokens (prefill-dominated), while the right panel varies output length with a fixed input length of 512 tokens (decode-dominated).
For prefill-dominated workloads, Route 4 achieves the highest throughput since each node operates independently without the overhead of data parallelism coordination. The disaggregated configurations (PD 1P3D and PD 2P2D) show competitive throughput at shorter input lengths but degrade at longer inputs where the prefill nodes become the bottleneck.
For decode-dominated workloads, Route 4 again leads, followed by PD 1P3D. PD 2P2D shows the lowest throughput in this regime, as its two decode nodes cannot match the decode capacity of other configurations.
Request Throughput#
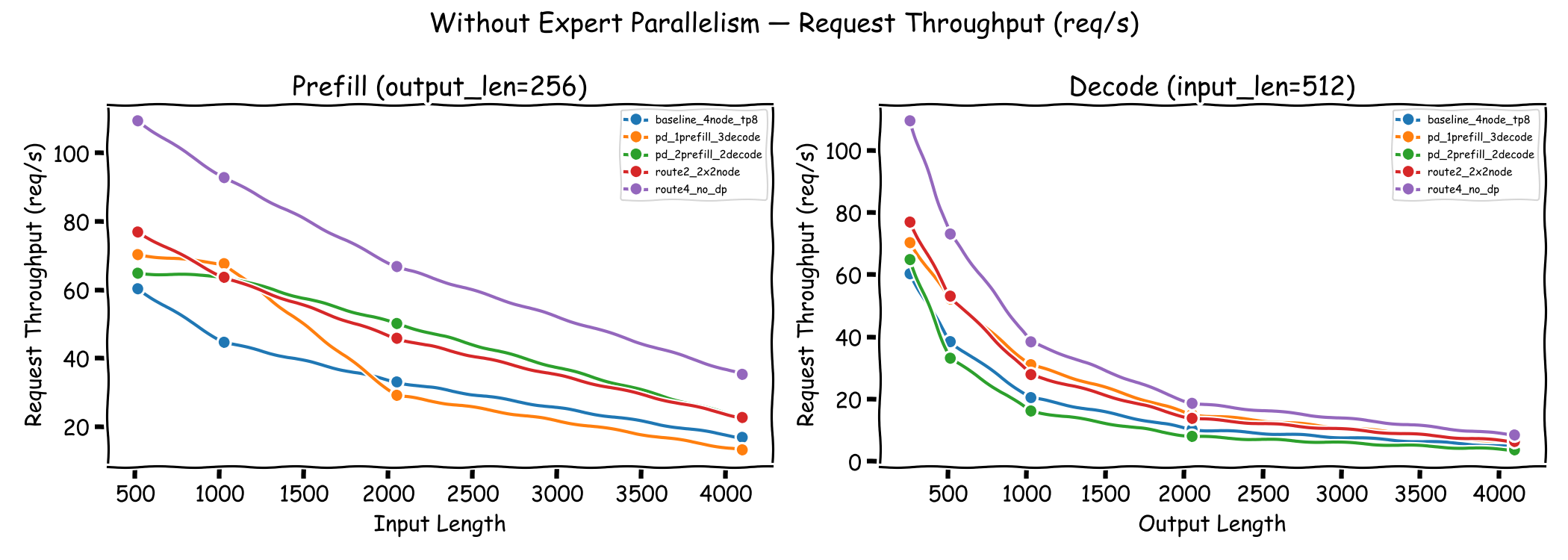
Request throughput follows a similar pattern. Route 4 consistently achieves the highest request throughput across all configurations. The disaggregated PD 1P3D configuration maintains reasonable request throughput for short inputs but drops significantly at longer input lengths (4096 tokens), where the single prefill node becomes saturated.
Time to First Token (TTFT)#
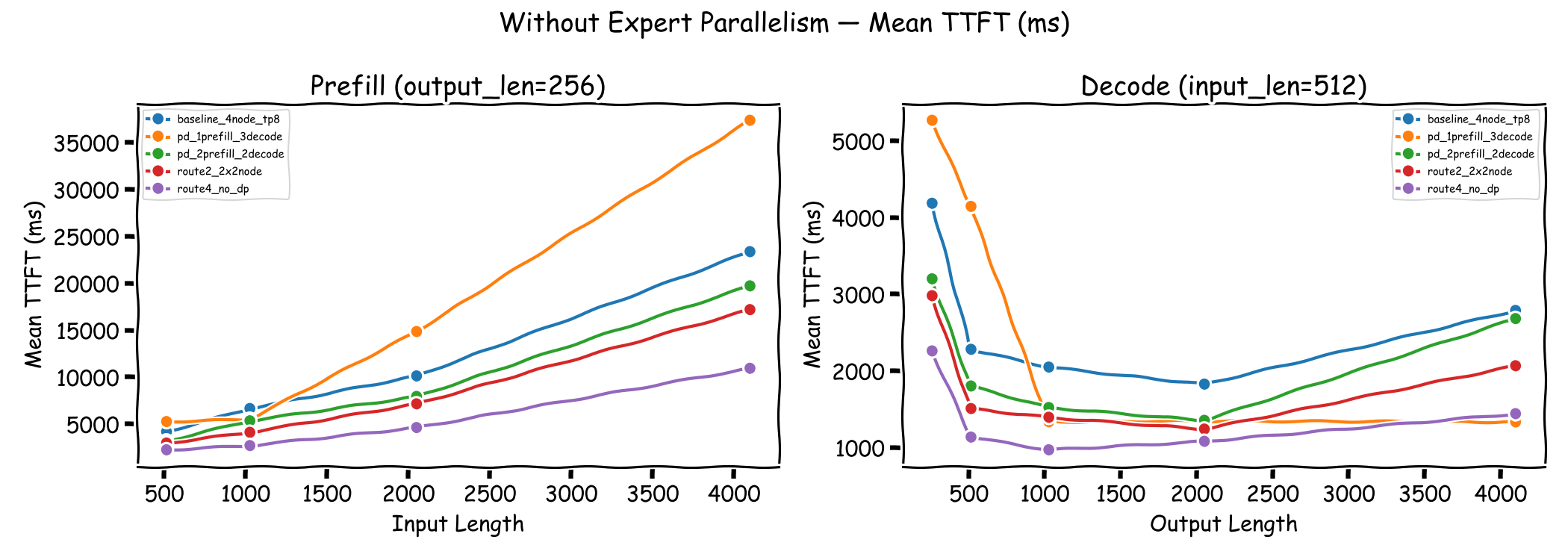
TTFT is critical for user-perceived latency. The baseline DP and Route 2 configurations show moderate TTFT that scales with input length. Route 4 achieves the lowest TTFT across all input lengths due to the absence of cross-node coordination.
The disaggregated configurations exhibit higher TTFT, particularly at longer input lengths. PD 1P3D shows TTFT exceeding 37 seconds at 4096 input tokens, as all prefill work funnels through a single node. PD 2P2D improves on this but still lags behind the non-disaggregated configurations. The additional latency from KV cache transfer over NIXL contributes to the elevated TTFT.
For decode-dominated workloads (right panel), the differences are smaller. At short output lengths (256–512 tokens), PD 1P3D shows 1–2 seconds higher TTFT than the baseline, as the KV cache transfer overhead is proportionally more significant. At longer output lengths (1024+ tokens), the disaggregated configurations converge with or improve upon the baseline, as the baseline suffers from increased prefill/decode contention under heavier concurrent decode load.
Inter-Token Latency (ITL)#
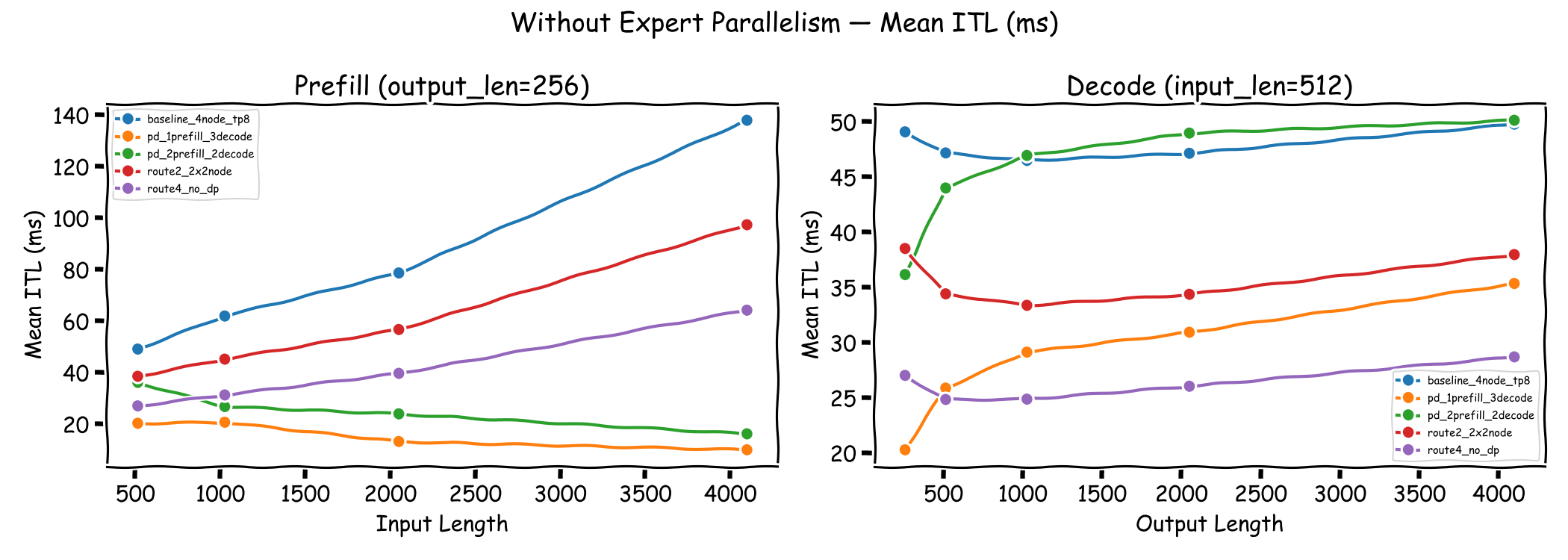
ITL measures the latency between consecutive generated tokens during the decode phase. This is where disaggregated serving shows its primary advantage.
In the prefill-dominated regime (left panel), PD 1P3D achieves the lowest ITL across all input lengths, with mean ITL as low as 10 ms at 4096 input tokens. By isolating decode nodes from prefill interference, the decode phase runs uninterrupted. PD 2P2D also shows reduced ITL compared to the baseline, though the benefit is less pronounced due to having fewer decode nodes. The baseline DP and Route configurations show higher ITL, particularly at longer input lengths where prefill and decode contend for the same GPU resources.
In the decode-dominated regime (right panel), Route 4 achieves the lowest ITL (~25–29 ms) since each node serves independently without cross-node coordination. Among the disaggregated configurations, PD 1P3D outperforms PD 2P2D due to its greater decode capacity (3 decode nodes vs. 2), maintaining ITL around 26–35 ms. PD 2P2D, with only 2 decode nodes, shows ITL comparable to the baseline (~45–50 ms). As output length increases, ITL gradually rises across all configurations, reflecting the growing decode load.
Discussion#
So, is disaggregated prefill/decode a silver bullet? The answer is clearly no — at least not under the conditions tested here. All benchmarks use randomly generated prompts, meaning every request produces a unique KV cache with zero prefix cache hit rate. This represents a worst-case scenario for disaggregated serving, where every prefill must be computed from scratch and the full KV cache must be transferred over the network. In production workloads with shared system prompts or repeated prefixes, prefix caching on prefill nodes could substantially reduce redundant computation and transfer volume, potentially shifting the balance in favor of disaggregation. Even so, the results reveal a set of sharp trade-offs that make disaggregation a specialized tool rather than a universal improvement:
ITL wins, but throughput depends on scaling: Disaggregated configurations deliver dramatically lower inter-token latency — PD 1P3D achieves as low as 10 ms ITL at long input lengths, up to 14× better than the baseline in prefill-dominated regimes and 1.4–2.4× better in decode-dominated regimes. The throughput and TTFT degradation observed here is partly an artifact of a fixed 4-node cluster: dedicating nodes to one role starves the other. In practice, prefill and decode pools can be scaled independently — adding more prefill nodes to eliminate the prefill bottleneck, or more decode nodes to increase token throughput. The challenge is finding the right ratio between prefill and decode capacity for a given workload, as over-provisioning either side increases cost without proportional benefit.
Prefill bottleneck is a hard constraint: With a fixed cluster size, dedicating nodes to prefill reduces decode capacity and vice versa. PD 1P3D suffers severe prefill saturation at long input lengths (TTFT > 37s at 4096 tokens), while PD 2P2D has fewer decode nodes, limiting decode throughput. Frameworks such as NVIDIA Dynamo aim to address this by dynamically scaling prefill and decode pools based on real-time demand, though this adds operational complexity.
Simple routing beats disaggregation on throughput: Route 4 (pure routing, no DP, no disaggregation) consistently achieves the highest throughput across all configurations by eliminating cross-node synchronization entirely. It also achieves the lowest TTFT in prefill-dominated workloads, though PD 1P3D edges it out on TTFT in decode-dominated regimes where the fixed 512-token input is short enough to avoid prefill saturation. This is a surprisingly strong baseline — for workloads where ITL is not the primary concern, stateless load-balanced independent nodes outperform both data parallelism and disaggregated configurations.
KV cache transfer is not free: The NIXL transfer over EFA adds measurable latency to TTFT in disaggregated configurations. This overhead is amortized for longer decode sequences but is noticeable for short output lengths, making disaggregation less attractive for short-response workloads.
In summary, disaggregated prefill/decode aims to optimize both TTFT and ITL by isolating the two phases, but achieving these goals is not guaranteed. KV cache transfer over the network introduces additional overhead that can negate the TTFT benefit, particularly at long input lengths where the transfer volume is large. While ITL improvements are consistently observed due to the elimination of prefill interference on decode nodes, the overall serving performance depends heavily on the prefill-to-decode ratio, workload characteristics, and network bandwidth. Teams considering this architecture should carefully profile their input/output length distributions, latency SLAs, and throughput requirements before committing to the added complexity.